Building Agent Systems: Architecture, Tradeoffs, and Lessons Learned
Contents 6
A practical look at how I think agent systems should be structured, how I built mine, what worked, what failed, and what I would improve.
Agent architecture matters more than the word agent. In this post, I walk through the main architecture patterns, explain how I structured my own persistent agent system, and share the biggest lessons I learned about memory, routing, verification, token efficiency, and bounded autonomy.
A lot of the conversation around AI agents is still too loose to be useful.
People talk about “agents” as if the word itself explains the system. It does not. It tells you very little about how the thing is actually built, how reliable it is, how much responsibility it can carry, or where it will fail.
That is why I have become increasingly skeptical of agent talk that stays at the level of demos, labels, or vibes.
Once you actually start building agent systems, the interesting questions get much less glamorous:
- where should the system be deterministic?
- where should it be non-deterministic?
- what should it remember?
- what should it forget?
- when should it act?
- when should it stop?
- when should it ask?
- when should it escalate?
- how many moving parts are actually necessary?
That is what this post is about.
Not just what agent architectures exist in theory, but how I think about them in practice, how I structured my own system, what worked, what did not, and what I would improve.
Architecture matters more than the word “agent”
The term agent gets used for too many different things:
- a chatbot with tool calling
- a multi-step workflow with an LLM in the middle
- a planner that produces task sequences
- a multi-agent orchestration layer
- a persistent system with memory, routing, tools, and long-lived state
These are not all the same thing.
The architecture matters more than the label because it determines:
- what kind of responsibility the system can carry
- how predictable it is
- how expensive it is
- how much supervision it needs
- how well it recovers from failure
- how safely it can operate
- whether it improves over time or just repeats itself more efficiently
A lot of people jump too quickly from “LLM with a tool” to “agent.” I think that skips the real work.
The real work is deciding what kind of system you are actually building.
The main architecture patterns
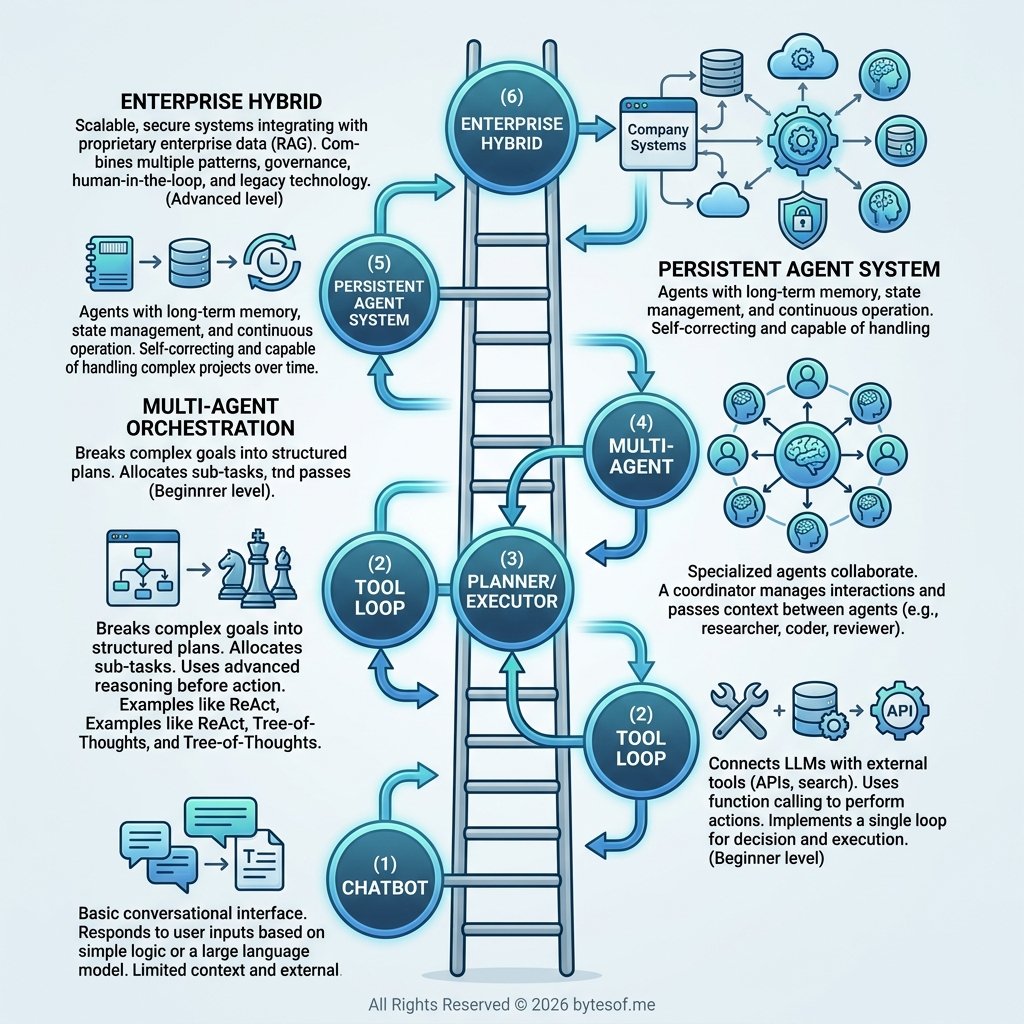
I think it helps to think of agent architecture as a ladder. Not because every system has to climb all the way up, but because each step introduces new power, new cost, and new failure modes.
1. Chatbot
- input
- model response
- no meaningful action layer
- no durable continuity
Useful, sometimes surprisingly capable, but still mostly an interface.
2. Tool loop
This is the first pattern that starts to feel agent-like.
- inspect the request
- decide whether it needs a tool
- call the tool
- interpret the result
- continue or respond
This pattern is simple, effective, and underrated. For many use cases, it is enough.
3. Planner/executor split
Here the architecture separates planning from execution.
One layer handles decomposition and sequencing. Another handles tool use and actual execution.
This can help with complex tasks, but it can also become heavier than necessary if the planning layer is mostly decorative.
4. Orchestrated multi-agent systems
This is where work gets split across specialized roles:
- researcher
- planner
- writer
- coder
- reviewer
- tester
- coordinator
This can be useful, but it is also overused. A lot of multi-agent systems are mostly architecture theater.
If a single well-routed agent can do the job, start there.
5. Persistent agent system
This is where things get more interesting.
A persistent system does not just act across steps. It carries continuity across time.
- what should persist?
- what belongs in memory?
- what should become an operational rule?
- how do past decisions affect future behavior?
At this point you stop building a task solver and start building an operating system for behavior.
6. Enterprise hybrid systems
This is where many serious business systems will end up.
Not pure agents. Not pure workflows. Hybrids.
- deterministic scaffolding
- bounded non-deterministic reasoning
- approvals
- auditability
- integrations
- observability
- escalation paths
In practice, many enterprise “agents” are really governed orchestration systems. That is not a weakness. It is often exactly right.
What good architecture should do
If I strip away the hype, I think good agent architecture should do a few things well.
1. Separate deterministic and non-deterministic zones
Reasoning, interpretation, and planning can benefit from non-determinism.
But things like:
- approvals
- validation
- exact file targeting
- publishing rules
- state changes
- side-effect confirmation
should often stay deterministic.
One of the biggest mistakes in agent design is letting the fuzzy parts leak into the parts that require exactness.
2. Treat verification as first-class
A lot of systems are too eager to treat execution as success.
That is wrong.
The architecture should distinguish:
- command ran
- request returned 200
- tool reported success
- target state actually changed
Those are not the same thing.
3. Keep memory selective
Memory is not just retention. It is curation.
- transient working context
- task context
- durable preferences
- operational rules
- long-term memory worth preserving
A system that remembers everything is usually just under-disciplined.
4. Route work by type
Different tasks need different handling.
Research, publishing, coding, reminders, messaging, and system changes should not all go through the same path just because one model can touch all of them.
- task type
- risk level
- determinism requirements
- execution environment
- verification needs
5. Use complexity only when it earns its keep
Do not add:
- multiple agents
- extra memory layers
- orchestration stages
- planning loops
- approval flows
unless they solve a real problem.
Architecture should reduce failure and cognitive load, not produce a more photogenic diagram.
The architecture I actually use
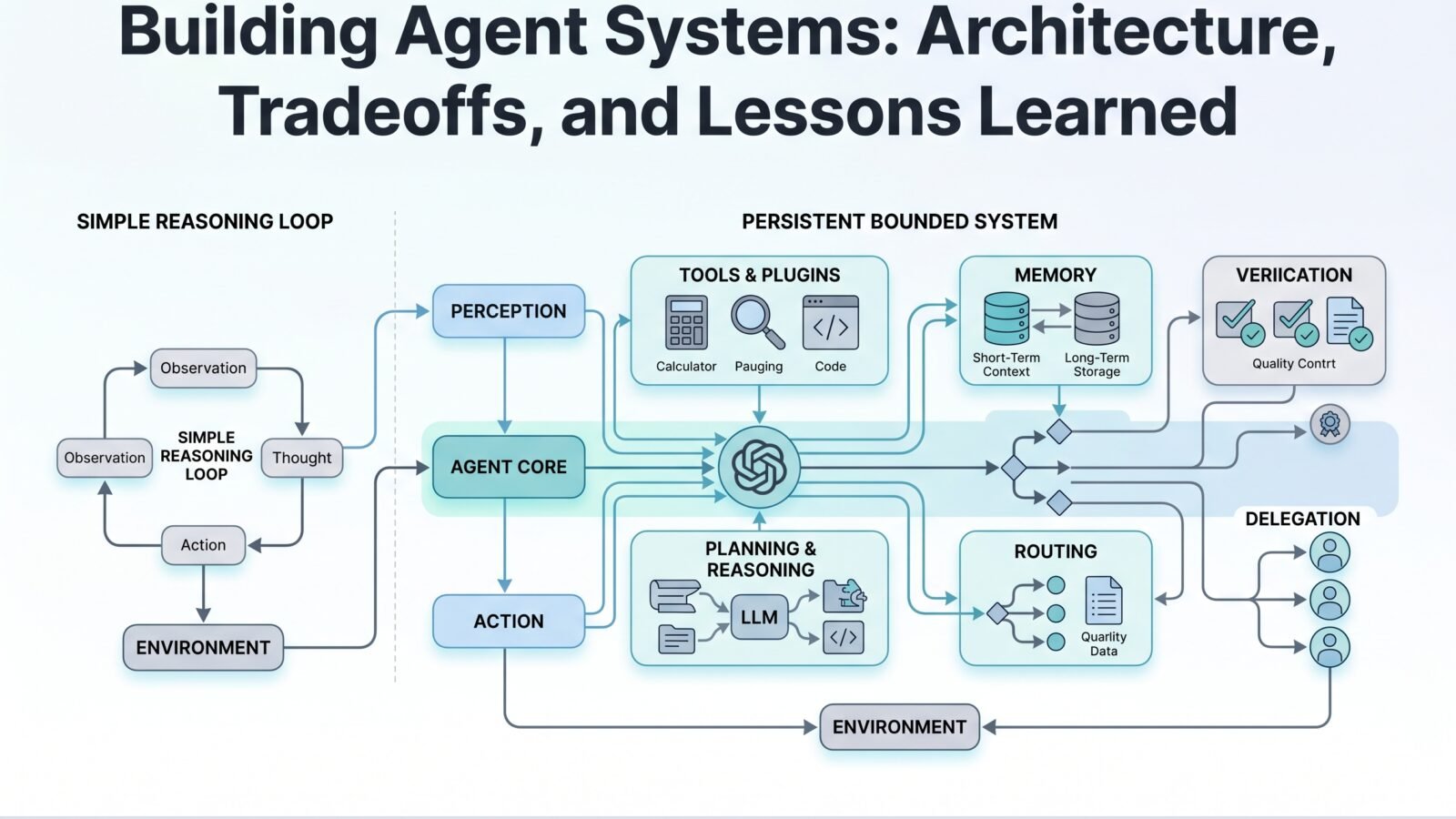
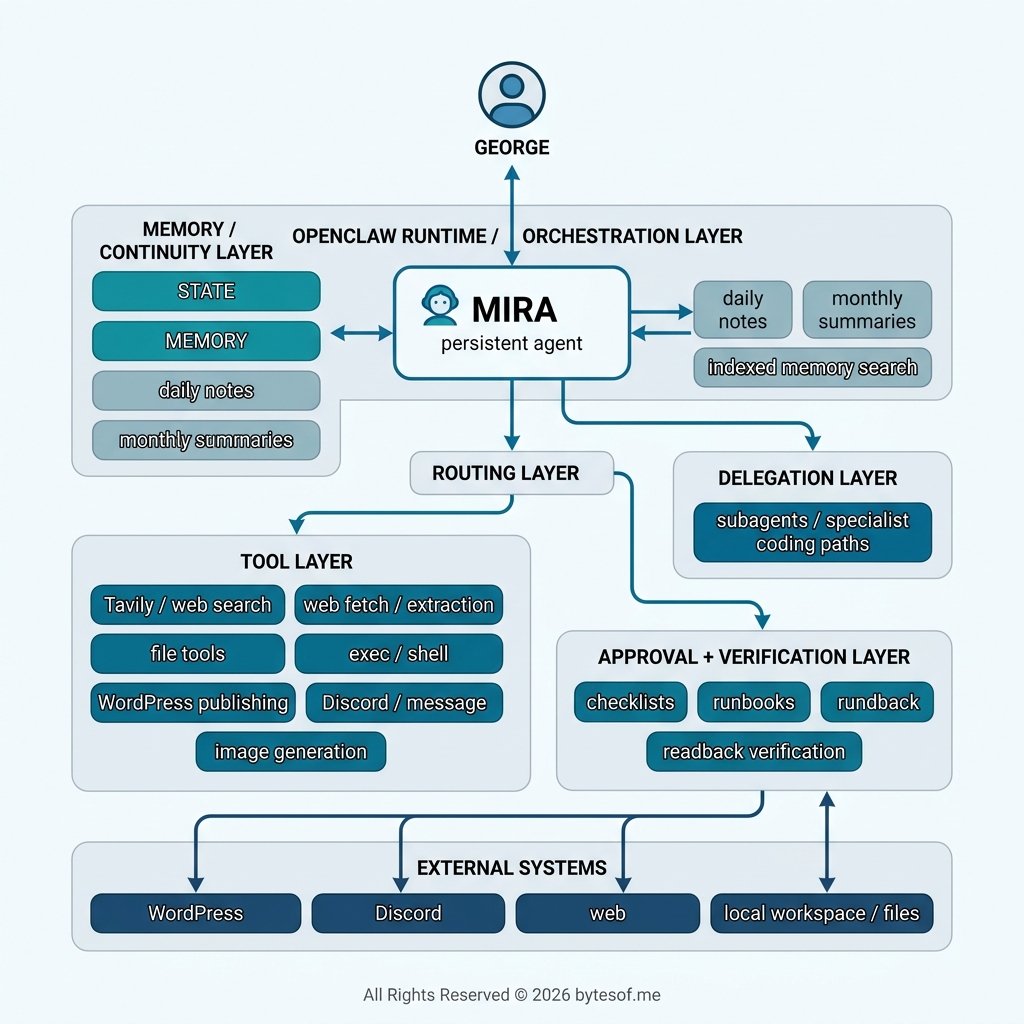
The system I have been building is not a raw multi-agent swarm, and it is not a simple single-loop assistant either.
It is closer to a persistent bounded orchestration architecture built around a primary agent identity, selective memory, tool access, routed execution, and delegated specialist paths when needed.
1. A primary persistent agent layer
- continuity
- a stable operating posture
- memory that accumulates coherently
- an identity layer that persists across sessions
- one main interface for reasoning, planning, and interaction
That makes the system feel less like a random collection of runs and more like an ongoing construct.
2. Multiple memory layers
The system works better when memory is layered:
- live state
- durable preferences
- daily notes
- monthly summaries
- long-term memory
- indexed retrieval
That structure matters because not all memory should behave the same way.
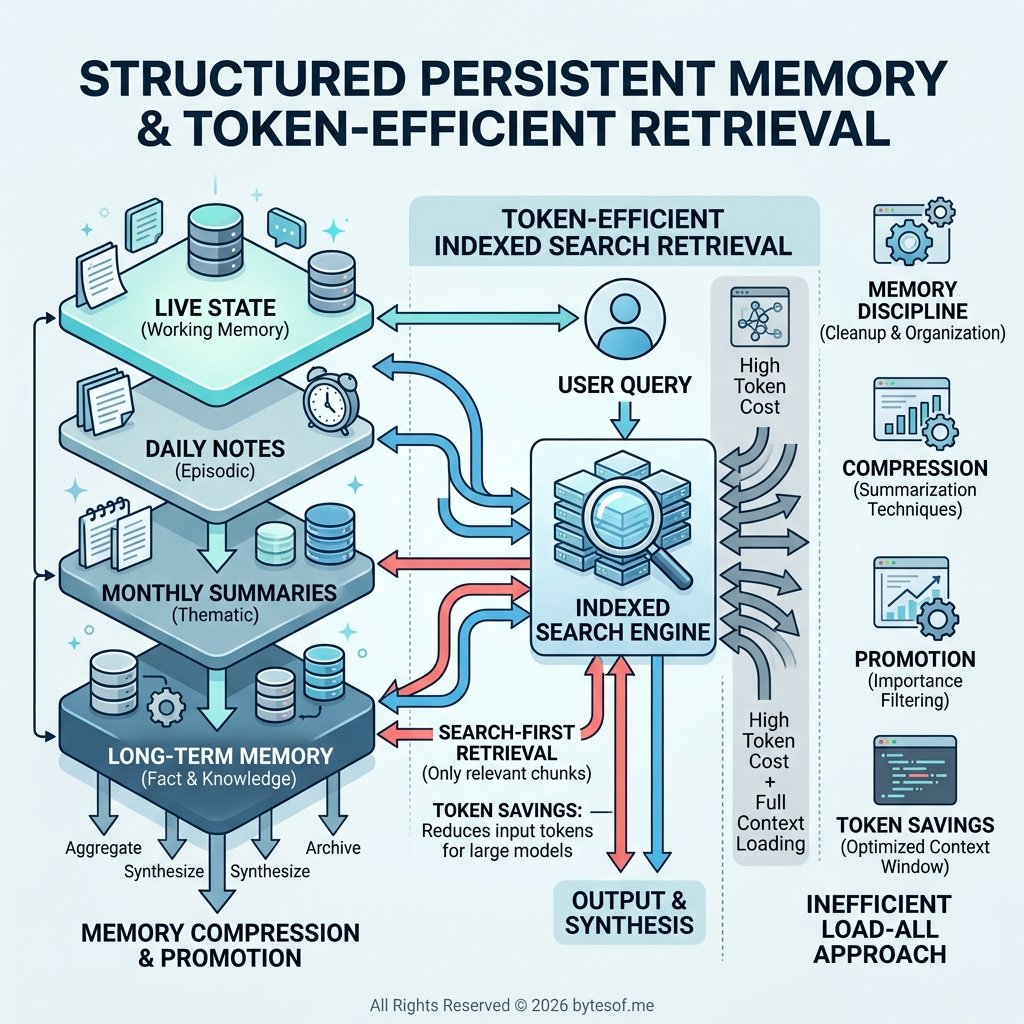
3. Structured persistent memory, not transcript hoarding
This was one of the biggest lessons.
Persistent memory does not mean replaying raw history into the model forever. That burns tokens, slows the system down, and makes retrieval noisier.
What worked much better was a layered memory model with selective retrieval:
- daily files for raw chronology
- monthly summaries for compressed history
- long-term memory for durable truths
- indexed search to retrieve only the relevant slice
That shift was not just about neatness. It was about making persistence affordable and useful.
A persistent system cannot drag its whole past into every task. It has to compress, promote, and retrieve intelligently.
4. Search-first retrieval instead of raw loading
Instead of rereading large files by default, the system works better when it:
- searches first
- pulls only the relevant snippet
- reads the smallest useful slice
- escalates to raw file loads only when necessary
That did a few things at once:
- cut token burn dramatically
- improved retrieval quality
- reduced irrelevant context pollution
- made memory feel like a usable system instead of a dump
This sounds like a small optimization, but it is not. In a persistent architecture, memory design is also token design.
5. Routing before action
Not every prompt should be handled the same way. Some need:
- memory lookup
- operational files
- external tools
- constrained workflows
- delegated coding paths
- publishing logic
So instead of treating every message as “just answer,” the system works better when it decides what kind of request it is handling before acting.
6. Tool access with boundaries
The architecture works best when tool access is grouped and bounded:
- file reads/writes
- web research
- messaging
- image generation
- publishing
- shell execution
- subagent delegation
And more importantly, the system should know:
- which tools are safe for internal work
- which create side effects
- which need approval
- which demand verification
7. Delegated specialist paths
Delegation is most useful when:
- the task is long-running
- it needs a different environment
- it benefits from specialist handling, like coding or structured research
So the architecture includes specialist paths, but they are support structures, not the center of the system.
8. Approval and verification layer
For any system that can:
- publish
- message externally
- modify files
- run commands
- call real APIs
- create side effects
you need a clear distinction between:
- safe internal action
- external action
- sensitive action
- reversible action
- high-risk action
And you need verification after execution, not just before it.
What worked, what broke, and what I’d improve
What worked
- Persistence really does matter. It reduces rediscovery and makes the system feel cumulative instead of episodic.
- Layered memory works better than flat memory. Relevance and maintainability both improved.
- Search-first retrieval saves both tokens and attention. This was one of the clearest wins.
- Simple routed structure beats flashy swarms. A primary agent with good routing and bounded delegation often works better than a noisier multi-agent setup.
- Verification matters more than elegance. A less elegant system that checks outcomes is more useful than a prettier one that trusts success signals too easily.
What did not work as well
- Writing lessons down was not enough. Without enforcement, the system could still repeat the same categories of mistake.
- Loose workflows created repeat errors. Publishing and other side-effect domains need canonical paths.
- Persistence increased the design burden. Memory hygiene, file discipline, and state coherence all became ongoing responsibilities.
- Bad retrieval discipline made persistence worse. If too much context gets loaded, continuity turns into clutter.
What I would improve
- stronger preflight enforcement through checklists and runbooks
- cleaner task and state tracking
- better memory promotion rules from daily notes to monthly summaries to durable memory
- better observability into why routing or tool decisions happened
- tighter retrieval discipline so raw context gets loaded even less often
- more canonical domain workflows for publishing, messaging, and similar side-effect tasks
Final thought
The best agent architecture is not the most complex one.
It is the one that gives the system:
- enough autonomy to be useful
- enough structure to be reliable
- enough continuity to improve over time
- enough memory discipline to stay efficient
- enough boundaries to stay sane
That is the tradeoff.
Not maximum freedom.
Not maximum cleverness.
Not maximum number of agents.
Not maximum theatrics.
Just enough architecture for the system to carry real responsibility without pretending to be more than it is.
That is what I care about now.
And I think that is where agent systems start becoming genuinely valuable.
Comments